Annotated Example: Matrix Correlator¶
Introduction¶
Matrix correlators, built from multiple sources and sinks,
greatly improve results for the excited states in the correlators.
Here we analyze  correlators using 4 sources/sinks using
a prior designed by
correlators using 4 sources/sinks using
a prior designed by corrfitter.EigenBasis.
A major challenge when studying excited states with multi-source
fits is the appearance in the fit of spurious states, with amplitudes that
are essentially zero, between the real states in the correlator.
These states contribute little to the correlators, because of their
vanishing amplitudes, but they usually have a strong negative impact
on the errors of states just below them and above them. They also can cause
the fitter to stall, taking 1000s of iterations to change nothing other
than the parameters of the spurious state.
corrfitter.EigenBasis addresses this problem by creating a prior that discourages
spurious states. It encodes the fact that only a small number of states
still couple to the matrix correlator by moderate values of t, and
therefore, that there exist linear combinations of the sources that
couple strongly to individual low-lying states but not the others. This
leaves little room for spurious low-lying states.
This example involves only two-point correlators. Priors generated
by corrfitter.EigenBasis are also useful in fits to three-point correlators,
with multiple eigen-bases if different types of hadron are involved.
The source code (etab.py) and data file
(etab.data) are included with the corrfitter distribution,
in the examples/ directory.
The data are from the HPQCD collaboration.
Code¶
The main method follows the template in Basic Fits, but
modified to handle the corrfitter.EigenBasis object basis:
from __future__ import print_function # makes this work for python2 and 3
import collections
import gvar as gv
import numpy as np
import corrfitter as cf
SHOWPLOTS = False # display plots at end of fits?
SOURCES = ['l', 'g', 'd', 'e']
KEYFMT = '1s0.{s1}{s2}'
TDATA = range(1, 24)
SVDCUT = 0.007
def main():
data, basis = make_data('etab.h5')
fitter = cf.CorrFitter(models=make_models())
p0 = None
for N in range(1, 8):
print(30 * '=', 'nterm =', N)
prior = make_prior(N, basis)
fit = fitter.lsqfit(data=data, prior=prior, p0=p0, svdcut=SVDCUT)
print(fit.format(pstyle=None if N < 7 else 'v'))
p0 = fit.pmean
print_results(fit, basis, prior, data)
if SHOWPLOTS:
fit.show_plots(save='etab.{}.png', view='ratio')
The eigen-basis is created by make_data('etab.h5'):
def make_data(filename):
data = gv.dataset.avg_data(cf.read_dataset(filename, grep='1s0'))
basis = cf.EigenBasis(
data, keyfmt=KEYFMT, srcs=SOURCES,
t=(1, 2), tdata=TDATA,
)
return data, basis
It reads Monte Carlo
data from file 'etab.h5', which is an hdf5-format file that
contains 16 hdf5 datasets of interest:
>>> import h5py
>>> dset = h5py.File('etab.h5', 'r')
>>> for v in dset.values():
... print(v)
<HDF5 dataset "1s0.dd": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.de": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.dg": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.dl": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.ed": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.ee": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.eg": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.el": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.gd": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.ge": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.gg": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.gl": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.ld": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.le": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.lg": shape (113, 23), type "<f8">
<HDF5 dataset "1s0.ll": shape (113, 23), type "<f8">
...
Each of these contains 113 Monte Carlo samples for a
different correlator evaluated at times t=1,2...23:
>>> print(dset['1s0.ll'][:, :])
[[ 0.360641 0.202182 0.134458 ..., 0.00118724 0.00091401 0.00070451]
[ 0.365291 0.210573 0.143632 ..., 0.00133125 0.0010258 0.00078879]
[ 0.362848 0.210732 0.143037 ..., 0.00130843 0.00101 0.00077627]
...,
[ 0.364053 0.209284 0.141544 ..., 0.00120762 0.00093206 0.0007196 ]
[ 0.365236 0.209835 0.139057 ..., 0.00116917 0.00089636 0.00069045]
[ 0.362479 0.20709 0.136687 ..., 0.00106393 0.0008269 0.00064707]]
The sixteen different correlators have tags given by:
KEYFMT.format(s1=s1, s2=s2)
where KEYFMT='1s0.{s1}{s2}', and s1 and s2 are
drawn from the list
SOURCES=['l', 'g', 'd', 'e'], which labels the sources and sinks used
to create the correlators.
The data are read in, and their means and covariance matrix computed
using gvar.dataset.avg_data(). corrfitter.EigenBasis then creates an
eigen-basis by solving a generalized eigenvalue problem involving the
matrices of correlators at t=1 and t=2. (One might want
larger t values generally, but these data are too noisy.)
The eigenanalysis constructs a set of eigen-sources
that are linear combinations of the original sources chosen
so that each eigen-source overlaps strongly with one of the
lowest four states in the correlator, and weakly with all the others.
This eigen-basis is used later to construct the prior.
A correlator fitter, called fitter, is created from the list of correlator
models returned by make_models():
def make_models():
models = []
for i, s1 in enumerate(SOURCES):
for s2 in SOURCES[i:]:
tfit = TDATA if s1 == s2 else TDATA[:12]
otherdata = None if s1 == s2 else KEYFMT.format(s1=s2, s2=s1)
models.append(
cf.Corr2(
datatag=KEYFMT.format(s1=s1, s2=s2),
tdata=TDATA, tfit=tfit,
a='etab.' + s1, b='etab.' + s2, dE='etab.dE',
otherdata=otherdata,
)
)
return models
There is one model for each correlator to be fit, so 16 in all. The keys
(datatag) for the correlator data are constructed from information
stored in the basis. Each correlator
has data (tdata) for t=1...23.
We fit all t values (tfit) for the diagonal elements of the
matrix correlator, but only about half the t values for other
correlators — the information at large t is highly correlated between
different correlators, and therefore somewhat redundant. The
amplitudes are labeled by 'etab.l', 'etab.g', 'etab.d', and
'etab.e' in the prior. The energy differences are labeled by 'etab.dE'.
We try fits with N=1,2..7 terms in the fit function. The number of
terms is encoded in the prior, which is constructed by
make_prior(N, basis):
def make_prior(N, basis):
return basis.make_prior(nterm=N, keyfmt='etab.{s1}')
The prior looks complicated
k prior[k]
------------ ---------------------------------------------------------------
etab.l [-0.51(17), -0.45(16), 0.50(17), 0.108(94), -0.06(87) ...]
etab.g [-0.88(27), 0.104(97), 0.051(92), -0.004(90), -0.13(90) ...]
etab.d [-0.243(86), -0.50(15), -0.268(91), -0.161(71), -0.21(60) ...]
etab.e [-0.211(83), -0.42(13), -0.30(10), 0.26(10), -0.12(61) ...]
log(etab.dE) [-1.3(2.3), -0.5(1.0), -0.5(1.0), -0.5(1.0), -0.5(1.0) ...]
but its underlying structure becomes clear if we project it unto the
eigen-basis using prior_eig = basis.apply(prior, keyfmt='etab.{s1}'):
k prior_eig[k]
------ ------------------------------------------------------------
etab.0 [1.00(30), .03(10), .03(10), .03(10), .2(1.0) ... ]
etag.1 [ .03(10), 1.00(30), .03(10), .03(10), .2(1.0) ... ]
etab.2 [ .03(10), .03(10), 1.00(30), .03(10), .2(1.0) ... ]
etab.3 [ .03(10), .03(10), .03(10), 1.00(30), .2(1.0) ... ]
The a priori expectation built into prior_eig (and therefore prior) is
that the ground state overlaps strongly with the first source in the
eigen-basis, and weakly with the other three. Similarly the first excited state
overlaps strongly with the second eigen-source, but none of the others. And so
on. The fifth and higher excited states can overlap with every eigen-source.
The priors for the energy differences between successive levels are based
upon the energies obtained from the eigenanalysis (basis.E): the dE
prior for the ground state is taken to be E0(E0), where E0=basis.E[0],
while for the other states it equals dE1(dE1), where
dE1=basis.E[1]-basis.E[0]. The prior specifies log-normal statistics for
etab.dE and so replaces it by log(etab.dE).
The fit is done by fitter.lsqfit(...). An SVD cut is needed
(SVDCUT=0.007) because the data are
heavily binned (to reduce the size of the corrfitter distribution).
The binning means there are too few random samples for
each data point to provide a good estimate of the data’s correlation
matrix without an SVD cut.
See Accurate Fits — SVD Cuts and the discussion below for more information.
Final results are printed out by print_results(...)
after the last fit is finished:
def print_results(fit, basis, prior, data):
print(30 * '=', 'Results\n')
print(basis.tabulate(fit.p, keyfmt='etab.{s1}'))
print(basis.tabulate(fit.p, keyfmt='etab.{s1}', eig_srcs=True))
E = np.cumsum(fit.p['etab.dE'])
outputs = collections.OrderedDict()
outputs['a*E(2s-1s)'] = E[1] - E[0]
outputs['a*E(3s-1s)'] = E[2] - E[0]
outputs['E(3s-1s)/E(2s-1s)'] = (E[2] - E[0]) / (E[1] - E[0])
inputs = collections.OrderedDict()
inputs['prior'] = prior
inputs['data'] = data
inputs['svdcut'] = fit.correction
print(gv.fmt_values(outputs))
print(gv.fmt_errorbudget(outputs, inputs, colwidth=18))
print('Prior:\n')
for k in ['etab.l', 'etab.g', 'etab.d', 'etab.e']:
print(
'{:13}{}'.format(k, list(prior[k]))
)
print()
prior_eig = basis.apply(prior, keyfmt='etab.{s1}')
for k in ['etab.0', 'etab.1', 'etab.2', 'etab.3']:
print(
'{:13}{}'.format(k, list(prior_eig[k]))
)
This method first writes out two tables listing energies and amplitudes for
the first 4 states in the correlator. The first table shows results for the
original sources, while the second is for the eigen-sources. The correlators
are from NRQCD so only energy differences are physical. The energy differences
for each of the first two excited states relative to the ground states are
stored in dictionary outputs. These are in lattice units. outputs
also contains the ratio of 3s-1s difference to the 2s-1s difference,
and here the lattice spacing cancels out. The code automatically handles
statistical correlations between different energies as it does the arithmetic
for outputs — the fit results are all gvar.GVars. The outputs
are tabulated using gvar.fmt_values(). An error budget is also
produced, using gvar.fmt_errorbudget(), showing how much error
for each quantity comes from uncertainties in the prior and data, and
from uncertainties introduced by the SVD cut.
Finally plots showing the data divided by the fit for each correlator are displayed (optionally).
Results¶
Running the code produces the following output for the last fit (N=7):
============================== nterm = 7
Least Square Fit:
chi2/dof [dof] = 0.32 [164] Q = 1 logGBF = 1277.1
Parameters:
etab.l 0 -0.50617 (88) [ -0.51 (17) ]
1 -0.397 (12) [ -0.45 (16) ]
2 0.414 (43) [ 0.50 (17) ]
3 0.148 (73) [ 0.108 (94) ]
4 -0.42 (26) [ -0.06 (87) ]
5 0.40 (33) [ -0.06 (87) ]
6 0.11 (46) [ -0.06 (87) ]
log(etab.dE) 0 -1.3620 (11) [ -1.3 (2.3) ]
1 -0.633 (20) [ -0.5 (1.0) ]
2 -1.084 (95) [ -0.5 (1.0) ]
3 -0.56 (30) [ -0.5 (1.0) ]
4 -1.01 (69) [ -0.5 (1.0) ]
5 -0.56 (95) [ -0.5 (1.0) ]
6 -0.60 (97) [ -0.5 (1.0) ]
etab.g 0 -0.8707 (16) [ -0.88 (27) ]
1 0.1424 (80) [ 0.104 (97) ]
2 0.058 (16) [ 0.051 (92) ]
3 0.033 (49) [ -0.004 (90) ]
4 -0.21 (12) [ -0.13 (90) ]
5 -0.13 (29) [ -0.13 (90) ]
6 0.31 (32) [ -0.13 (90) ]
etab.d 0 -0.21618 (48) [ -0.243 (86) ]
1 -0.416 (11) [ -0.50 (15) ]
2 -0.246 (29) [ -0.268 (91) ]
3 -0.113 (51) [ -0.161 (71) ]
4 -0.25 (14) [ -0.21 (60) ]
5 -0.03 (33) [ -0.21 (60) ]
6 -0.32 (27) [ -0.21 (60) ]
etab.e 0 -0.19707 (43) [ -0.211 (83) ]
1 -0.349 (10) [ -0.42 (13) ]
2 -0.285 (26) [ -0.30 (10) ]
3 0.261 (59) [ 0.26 (10) ]
4 -0.19 (17) [ -0.12 (61) ]
5 -0.09 (34) [ -0.12 (61) ]
6 -0.37 (27) [ -0.12 (61) ]
----------------------------------------------------
etab.dE 0 0.25616 (28) [ 0.27 (62) ]
1 0.531 (11) [ 0.62 (62) ]
2 0.338 (32) [ 0.62 (62) ]
3 0.57 (17) [ 0.62 (62) ]
4 0.36 (25) [ 0.62 (62) ]
5 0.57 (54) [ 0.62 (62) ]
6 0.55 (54) [ 0.62 (62) ]
Settings:
svdcut/n = 0.007/130 tol = (1e-08*,1e-10,1e-10) (itns/time = 82/0.5)
The  per degree of freedom is unusually small because of the
large SVD cut (see below). This fit required 169 iterations,
but took only a couple of seconds
on a laptop. The results are almost identical to those from
per degree of freedom is unusually small because of the
large SVD cut (see below). This fit required 169 iterations,
but took only a couple of seconds
on a laptop. The results are almost identical to those from N=6 and N=8.
The final energies and amplitudes for the original sources are listed as
E etab.l etab.g etab.d etab.e
=================================================================
0 0.25616(28) -0.50617(88) -0.8707(16) -0.21618(48) -0.19707(43)
1 0.787(11) -0.397(12) 0.1424(80) -0.416(11) -0.349(10)
2 1.126(34) 0.414(43) 0.058(16) -0.246(29) -0.285(26)
3 1.70(17) 0.148(73) 0.033(49) -0.113(51) 0.261(59)
while for the eigen-sources they are
E etab.0 etab.1 etab.2 etab.3
================================================================
0 0.25616(28) 0.9817(18) 0.0068(10) -0.00168(66) 0.00156(48)
1 0.787(11) -0.0339(81) 0.890(17) -0.022(21) 0.0094(97)
2 1.126(34) 0.016(17) 0.068(59) 0.863(43) -0.003(28)
3 1.70(17) -0.020(58) -0.023(85) 0.036(87) 0.899(88)
The latter shows that the eigen-sources align quite well with the first four states, as hoped. The errors, especially for the first three states, are much smaller than the prior errors, which indicates strong signals for these states.
Finally values and an error budget are presented for the 2s-1s and 3s-1s energy differences (in lattice units) and the ratio of the two:
Values:
a*E(2s-1s): 0.531(11)
a*E(3s-1s): 0.870(34)
E(3s-1s)/E(2s-1s): 1.637(62)
Partial % Errors:
a*E(2s-1s) a*E(3s-1s) E(3s-1s)/E(2s-1s)
--------------------------------------------------------------------------
prior: 0.72 2.23 2.08
data: 1.37 2.20 1.93
svdcut: 1.31 2.28 2.50
--------------------------------------------------------------------------
total: 2.03 3.87 3.78
The first excited state is obviously more accurately determined than the second state, but the fit improves our knowledge of both. The energies for the fifth and higher states merely echo the a priori information in the prior — the data are not sufficiently accurate to add much new information to what was in the prior. The prior is less important for the three quantities tabulated here. The dominant source of error in each case comes from either the SVD cut or the statistical errors in the data.
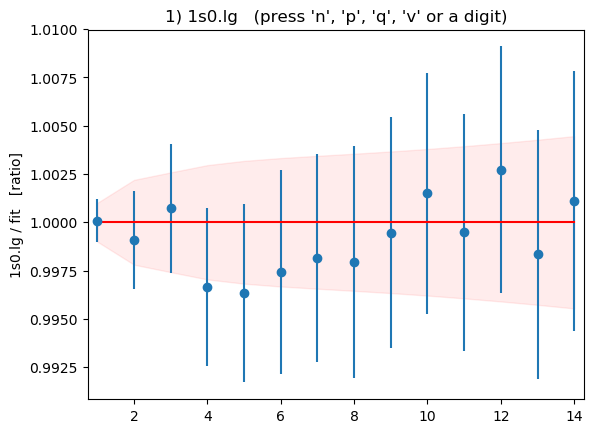
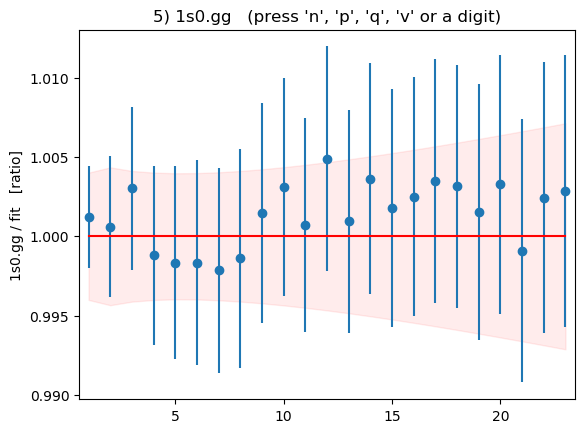
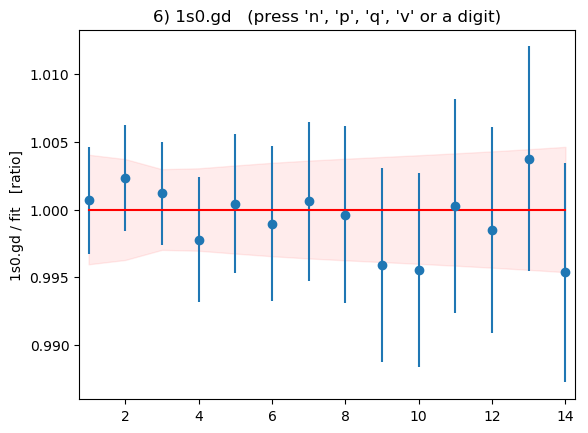
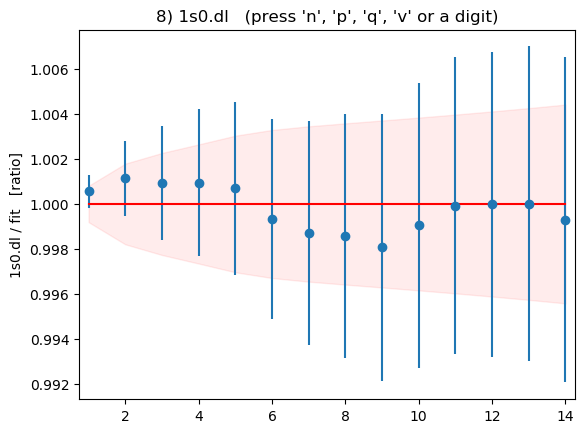
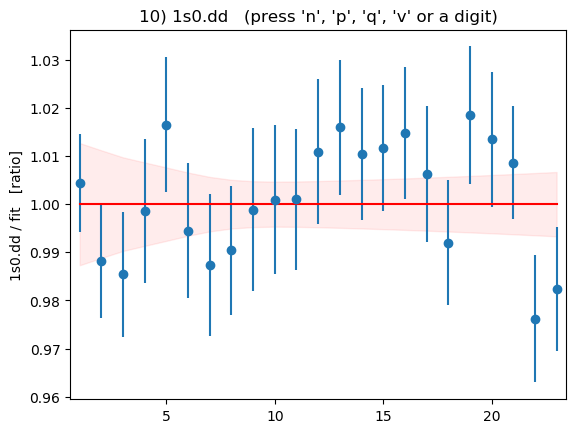
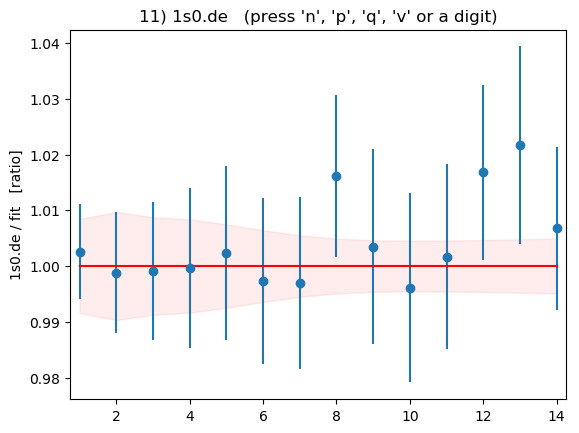
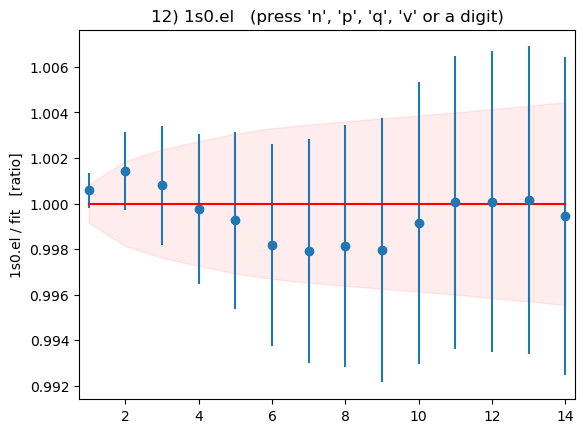
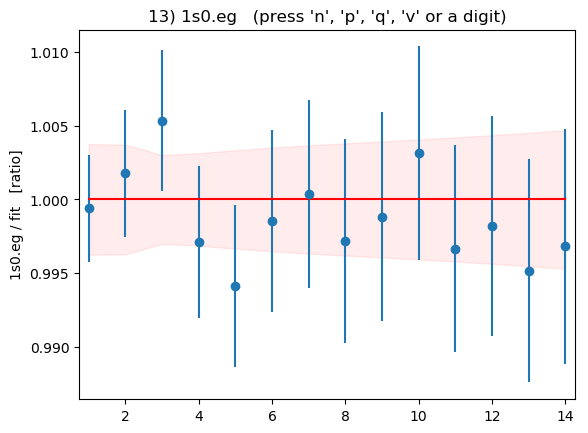
Summary plots showing the data divided by the fit as a function of t
for each of the 16 correlators is shown below:

|
|

|

|

|
|
|

|
|

|
|
|
|
|

|
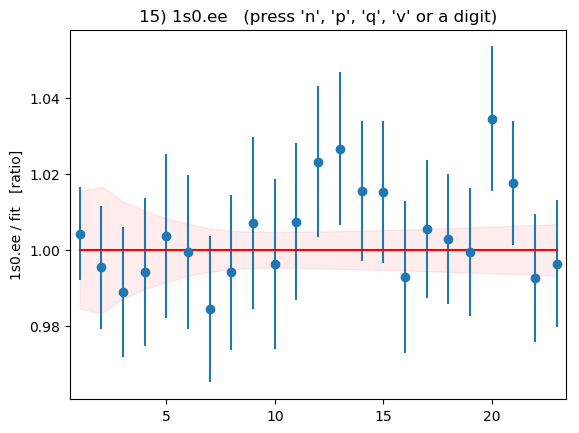
|
These plots are displayed by the code above if flag
DISPLAYPLOTS = True is set at the beginning of the code. The points with
error bars are correlator data points; the fit result is 1.0 in these
plots; and the dashed lines show the uncertainty in the fit function
values for the best-fit parameters. Fit and data agree well for
all correlators and all t values. As expected, strong correlations
exist between points with near-by ts.
Setting the SVD Cut¶
As mentioned above, an SVD cut (SVDCUT=0.007)
was needed for this fit because there
are too few random samples of the correlators. The problem is that
the smallest eigenvalues of the data’s correlation matrix
are then underestimated, making the correlation matrix
too singular for use in the fit (see
Accurate Fits — SVD Cuts). The SVD cut adds extra uncertainty to the fit data
to correct for these eigenvalues, making the correlation matrix usable.
The value of the SVD cut was determined using a short script that combines
import gvar as gv
import corrfitter as cf
def main():
dset = cf.read_dataset('etab.h5', grep='1s0')
s = gv.dataset.svd_diagnosis(dset, models=make_models())
print('svdcut =', s.svdcut)
s.plot_ratio(show=True)
with the code for make_models() described above.
Here gv.dataset.svd_diagnosis(...) compares the exact eigenvalues of the
correlation matrix with bootstrap estimates of the eigenvalues. The ratio of
bootstrap estimates to exact values is shown in the plot (from
s.plot_ratio(show=True)):

This shows that the SVD cut should be around 0.007, which is where the ratio falls below one.
This is a relatively large SVD cut affecting many of the correlation
matrice’s eigenmodes (233 out of 260). As a result the fit’s
is quite small. As discussed in Goodness of Fit, we need to add
extra noise to the data if we want to use to evaluate fit quality.
Adding the following code
# check fit quality by adding noise
print('\n==================== add svd, prior noise')
noisy_fit = fitter.lsqfit(
data=data, prior=prior, p0=fit.pmean, svdcut=SVDCUT,
noise=True,
)
print(noisy_fit.format(pstyle=None))
dE = fit.p['etab.dE'][:3]
noisy_dE = noisy_fit.p['etab.dE'][:3]
print(' dE:', dE)
print('noisy dE:', noisy_dE)
print(' ', gv.fmt_chi2(gv.chi2(dE - noisy_dE)))
to the end of the main() method results in a second fit with noise
associated with both the SVD cut and the prior. The result is a good fit,
even with the additional noise:
==================== add svd, prior noise
Least Square Fit:
chi2/dof [dof] = 1 [164] Q = 0.33 logGBF = 1221.6
Settings:
svdcut/n = 0.007/130* tol = (1e-08*,1e-10,1e-10) (itns/time = 95/0.6)
dE: [0.25616(28) 0.531(11) 0.338(32)]
noisy dE: [0.25617(28) 0.5415(90) 0.345(31)]
chi2/dof = 0.38 [3] Q = 0.77
Fit Stability¶
It is a good idea in fits like this one to test the stability of the results to significant changes in the prior. This is especially true for quantities like the 3s-1s splitting that involve more highly excited states. The default prior in effect assigns each of the four sources in the new basis to one of the four states in the correlator with the lowest energies. Typically the actual correspondence between source and low-energy state weakens as the energy increases. So an obvious test is to rerun the fit but with a prior that associates states with only three of the sources, leaving the fourth source unconstrained. This is done by replacing
def make_prior(N, basis):
return basis.make_prior(nterm=N, keyfmt='etab.{s1}')
with
def make_prior(N, basis):
return basis.make_prior(nterm=N, keyfmt='etab.{s1}', states=[0, 1, 2])
in the code. The states option in the second basis.make_prior(...)
assigns the three lowest lying states (in order of increasing energy)
to the first three eigen-sources, but leaves the fourth and higher states
unassigned. The prior for the amplitudes projected onto the eigen-basis
then becomes
k prior_eig[k]
------ ----------------------------------------------------------
etab.0 [1.00(30), .03(10), .03(10), .2(1.0), .2(1.0) ... ]
etab.1 [ .03(10), 1.00(30), .03(10), .2(1.0), .2(1.0) ... ]
etab.2 [ .03(10), .03(10), 1.00(30), .2(1.0), .2(1.0) ... ]
etab.3 [ .2(1.0), .2(1.0), .2(1.0), .2(1.0), .2(1.0) ... ]
where now no strong assumption is made about the overlaps of the first three eigen-sources with the fourth state, or about the overlap of the fourth source with any state. Running with this (more conservative) prior gives the following results for the last fit and summary:
============================== nterm = 7
Least Square Fit:
chi2/dof [dof] = 0.32 [164] Q = 1 logGBF = 1270.3
Parameters:
etab.l 0 -0.50587 (94) [ -0.51 (17) ]
1 -0.395 (13) [ -0.45 (16) ]
2 0.417 (44) [ 0.50 (17) ]
3 -0.18 (28) [ -0.06 (87) ]
4 0.16 (27) [ -0.06 (87) ]
5 0.55 (10) [ -0.06 (87) ]
6 -0.08 (46) [ -0.06 (87) ]
log(etab.dE) 0 -1.3621 (11) [ -1.3 (2.3) ]
1 -0.632 (19) [ -0.5 (1.0) ]
2 -1.10 (10) [ -0.5 (1.0) ]
3 -0.85 (66) [ -0.5 (1.0) ]
4 -1.02 (71) [ -0.5 (1.0) ]
5 -0.67 (85) [ -0.5 (1.0) ]
6 -0.61 (97) [ -0.5 (1.0) ]
etab.g 0 -0.8701 (17) [ -0.88 (27) ]
1 0.146 (10) [ 0.104 (97) ]
2 0.061 (33) [ 0.051 (92) ]
3 -0.201 (62) [ -0.13 (90) ]
4 -0.05 (14) [ -0.13 (90) ]
5 0.09 (14) [ -0.13 (90) ]
6 0.13 (17) [ -0.13 (90) ]
etab.d 0 -0.21609 (51) [ -0.243 (86) ]
1 -0.4168 (99) [ -0.50 (15) ]
2 -0.240 (35) [ -0.268 (91) ]
3 -0.12 (11) [ -0.21 (60) ]
4 -0.07 (17) [ -0.21 (60) ]
5 0.07 (30) [ -0.21 (60) ]
6 -0.47 (17) [ -0.21 (60) ]
etab.e 0 -0.19697 (46) [ -0.211 (83) ]
1 -0.347 (10) [ -0.42 (13) ]
2 -0.275 (38) [ -0.30 (10) ]
3 -0.19 (19) [ -0.12 (61) ]
4 0.31 (14) [ -0.12 (61) ]
5 -0.06 (21) [ -0.12 (61) ]
6 -0.26 (23) [ -0.12 (61) ]
----------------------------------------------------
etab.dE 0 0.25613 (29) [ 0.27 (62) ]
1 0.532 (10) [ 0.62 (62) ]
2 0.333 (34) [ 0.62 (62) ]
3 0.43 (28) [ 0.62 (62) ]
4 0.36 (25) [ 0.62 (62) ]
5 0.51 (44) [ 0.62 (62) ]
6 0.55 (53) [ 0.62 (62) ]
Settings:
svdcut/n = 0.007/130 tol = (1e-08*,1e-10,1e-10) (itns/time = 58/0.4)
============================== Results
E etab.l etab.g etab.d etab.e
=================================================================
0 0.25613(29) -0.50587(94) -0.8701(17) -0.21609(51) -0.19697(46)
1 0.788(10) -0.395(13) 0.146(10) -0.4168(99) -0.347(10)
2 1.121(37) 0.417(44) 0.061(33) -0.240(35) -0.275(38)
3 1.55(29) -0.18(28) -0.201(62) -0.12(11) -0.19(19)
E etab.0 etab.1 etab.2 etab.3
================================================================
0 0.25613(29) 0.9810(19) 0.0069(10) -0.00168(66) 0.00156(50)
1 0.788(10) -0.038(12) 0.891(15) -0.022(20) 0.014(11)
2 1.121(37) 0.011(41) 0.060(58) 0.854(54) 0.008(39)
3 1.55(29) 0.251(47) 0.15(23) 0.08(37) -0.20(37)
Values:
a*E(2s-1s): 0.532(10)
a*E(3s-1s): 0.865(37)
E(3s-1s)/E(2s-1s): 1.627(65)
Partial % Errors:
a*E(2s-1s) a*E(3s-1s) E(3s-1s)/E(2s-1s)
--------------------------------------------------------------------------
prior: 0.59 2.67 2.44
data: 1.36 2.22 1.95
svdcut: 1.23 2.42 2.51
--------------------------------------------------------------------------
total: 1.93 4.23 4.01
The energies and amplitudes for the first three states are almost unchanged, which gives us confidence in the original results. Results for the fourth and higher states have larger errors, as expected.
Note that while the value for this last fit is almost identical to
that in the original fit, the Bayes Factor (from logGBF) is
exp(1277.1-1270.3)=899 times larger for the original fit. The Bayes Factor
gives us a sense of which prior the data prefer. Specifically it says that
our Monte Carlo data are 899 times more likely to have come from a model
with the original prior than from one with the more conservative prior. This
further reinforces our confidence in the original results.
Alternative Organization¶
Our fit uses the corrfitter.EigenBasis to construct a special prior for the fit,
but leaves the correlators unchanged. An alternative approach is to project
the correlators unto the eigen-basis, and then to fit them with a fit function
defined directly in terms of the eigen-basis. This approach is conceptually
identical to that above, but in practice it gives somewhat different
results since the SVD cut enters differently. A version of the code above
that uses this approach is:
from __future__ import print_function # makes this work for python2 and 3
import collections
import gvar as gv
import numpy as np
import corrfitter as cf
DISPLAYPLOTS = False # display plots at end of fits?
SOURCES = ['l', 'g', 'd', 'e']
EIG_SOURCES = ['0', '1', '2', '3'] # 1a
KEYFMT = '1s0.{s1}{s2}'
TDATA = range(1, 24)
SVDCUT = 0.06 # 2
def main():
data, basis = make_data('etab.h5')
fitter = cf.CorrFitter(models=make_models())
p0 = None
for N in range(1, 8):
print(30 * '=', 'nterm =', N)
prior = make_prior(N, basis)
fit = fitter.lsqfit(data=data, prior=prior, p0=p0, svdcut=SVDCUT)
print(fit.format(pstyle=None if N < 7 else 'm'))
p0 = fit.pmean
print_results(fit, basis, prior, data)
if DISPLAYPLOTS:
fitter.display_plots()
print('\n==================== add svd, prior noise')
noisy_fit = fitter.lsqfit(
data=data, prior=prior, p0=fit.pmean, svdcut=SVDCUT,
noise=True,
)
print(noisy_fit.format(pstyle=None))
dE = fit.p['etab.dE'][:3]
noisy_dE = noisy_fit.p['etab.dE'][:3]
print(' dE:', dE)
print('noisy dE:', noisy_dE)
print(' ', gv.fmt_chi2(gv.chi2(dE - noisy_dE)))
def make_data(filename):
data = gv.dataset.avg_data(cf.read_dataset(filename))
basis = cf.EigenBasis(
data, keyfmt='1s0.{s1}{s2}', srcs=['l', 'g', 'd', 'e'],
t=(1,2), tdata=range(1,24),
)
return basis.apply(data, keyfmt='1s0.{s1}{s2}'), basis # 3
def make_models():
models = []
for i, s1 in enumerate(EIG_SOURCES): # 1b
for s2 in EIG_SOURCES[i:]: # 1c
tfit = TDATA if s1 == s2 else TDATA[:12]
otherdata = None if s1 == s2 else KEYFMT.format(s1=s2, s2=s1)
models.append(
cf.Corr2(
datatag=KEYFMT.format(s1=s1, s2=s2),
tdata=TDATA, tfit=tfit,
a='etab.' + s1, b='etab.' + s2, dE='etab.dE',
otherdata=otherdata,
)
)
return models
def make_prior(N, basis):
return basis.make_prior(nterm=N, keyfmt='etab.{s1}', eig_srcs=True) # 4
def print_results(fit, basis, prior, data):
print(30 * '=', 'Results\n')
print(basis.tabulate(fit.p, keyfmt='etab.{s1}'))
print(basis.tabulate(fit.p, keyfmt='etab.{s1}', eig_srcs=True))
E = np.cumsum(fit.p['etab.dE'])
outputs = collections.OrderedDict()
outputs['a*E(2s-1s)'] = E[1] - E[0]
outputs['a*E(3s-1s)'] = E[2] - E[0]
outputs['E(3s-1s)/E(2s-1s)'] = (E[2] - E[0]) / (E[1] - E[0])
inputs = collections.OrderedDict()
inputs['prior'] = prior
inputs['data'] = data
inputs['svdcut'] = fit.correction
print(gv.fmt_values(outputs))
print(gv.fmt_errorbudget(outputs, inputs, colwidth=18))
if __name__ == '__main__':
gv.ranseed(1)
main()
This code has four changes from the original: it uses the eigen-sources for
building the models (#1); the SVD cut is different (#2); the data
are projected onto the eigen-basis (#3); and the prior is defined
for the eigen-sources (#4).
The fit results from the new code are very similar to before; there is little difference between the two approaches in this case:
============================== nterm = 7
Least Square Fit:
chi2/dof [dof] = 0.32 [164] Q = 1 logGBF = 1141.6
Parameters:
etab.0 0 0.9811 (23) [ 1.00 (30) ]
1 -0.0320 (83) [ 0.03 (10) ]
2 0.030 (12) [ 0.03 (10) ]
3 -0.048 (39) [ 0.03 (10) ]
4 0.35 (15) [ 0.2 (1.0) ]
5 0.17 (42) [ 0.2 (1.0) ]
6 -0.12 (49) [ 0.2 (1.0) ]
log(etab.dE) 0 -1.3625 (14) [ -1.3 (2.3) ]
1 -0.628 (23) [ -0.5 (1.0) ]
2 -1.14 (11) [ -0.5 (1.0) ]
3 -0.43 (29) [ -0.5 (1.0) ]
4 -0.65 (82) [ -0.5 (1.0) ]
5 -0.65 (95) [ -0.5 (1.0) ]
6 -0.64 (97) [ -0.5 (1.0) ]
etab.1 0 0.00625 (92) [ 0.03 (10) ]
1 0.896 (19) [ 1.00 (30) ]
2 0.052 (57) [ 0.03 (10) ]
3 -0.057 (77) [ 0.03 (10) ]
4 0.27 (46) [ 0.2 (1.0) ]
5 0.14 (68) [ 0.2 (1.0) ]
6 0.96 (48) [ 0.2 (1.0) ]
etab.2 0 -0.00238 (30) [ 0.03 (10) ]
1 -0.021 (21) [ 0.03 (10) ]
2 0.844 (48) [ 1.00 (30) ]
3 0.024 (87) [ 0.03 (10) ]
4 -0.41 (55) [ 0.2 (1.0) ]
5 0.71 (44) [ 0.2 (1.0) ]
6 -0.04 (78) [ 0.2 (1.0) ]
etab.3 0 0.00155 (13) [ 0.03 (10) ]
1 0.0082 (90) [ 0.03 (10) ]
2 0.001 (21) [ 0.03 (10) ]
3 0.94 (10) [ 1.00 (30) ]
4 0.18 (16) [ 0.2 (1.0) ]
5 0.08 (25) [ 0.2 (1.0) ]
6 0.04 (32) [ 0.2 (1.0) ]
---------------------------------------------------
etab.dE 0 0.25602 (35) [ 0.27 (62) ]
1 0.534 (12) [ 0.62 (62) ]
2 0.319 (36) [ 0.62 (62) ]
3 0.65 (19) [ 0.62 (62) ]
4 0.52 (43) [ 0.62 (62) ]
5 0.52 (50) [ 0.62 (62) ]
6 0.53 (51) [ 0.62 (62) ]
Settings:
svdcut/n = 0.06/133 tol = (1e-08*,1e-10,1e-10) (itns/time = 72/0.5)
============================== Results
E etab.l etab.g etab.d etab.e
================================================================
0 0.25602(35) -0.5060(12) -0.8703(21) -0.21562(61) -0.19652(54)
1 0.790(12) -0.400(14) 0.1416(73) -0.420(11) -0.352(11)
2 1.109(36) 0.404(39) 0.042(15) -0.237(29) -0.275(27)
3 1.76(19) 0.176(66) 0.053(36) -0.093(45) 0.296(52)
E etab.0 etab.1 etab.2 etab.3
=================================================================
0 0.25602(35) 0.9811(23) 0.00625(92) -0.00238(30) 0.00155(13)
1 0.790(12) -0.0320(83) 0.896(19) -0.021(21) 0.0082(90)
2 1.109(36) 0.030(12) 0.052(57) 0.844(48) 0.001(21)
3 1.76(19) -0.048(39) -0.057(77) 0.024(87) 0.94(10)
Values:
a*E(2s-1s): 0.534(12)
a*E(3s-1s): 0.853(36)
E(3s-1s)/E(2s-1s): 1.599(70)
Partial % Errors:
a*E(2s-1s) a*E(3s-1s) E(3s-1s)/E(2s-1s)
--------------------------------------------------------------------------
prior: 0.62 1.87 1.74
data: 1.34 2.08 1.65
svdcut: 1.76 3.10 3.69
--------------------------------------------------------------------------
total: 2.30 4.17 4.40
Projecting the correlators onto the eigen-basis makes off-diagonal correlators much less important to the fit. Results are essentially unchanged if only the diagonal elements of the matrix of correlators are used in the fit.