Annotated Example: Transition Form Factor and Mixing¶
Introduction¶
Here we describe a complete Python code that uses corrfitter
to calculate the transition matrix element or form factor from
an  meson to a
meson to a  meson, together with the masses and amplitudes
of these mesons. A very similar code, for (speculative) - mixing,
is described at the end.
meson, together with the masses and amplitudes
of these mesons. A very similar code, for (speculative) - mixing,
is described at the end.
The form factor example combines data from two-point correlators, for the
amplitudes and energies, with data from three-point correlators,
for the transition matrix element. We fit all of the correlators
together, in a single fit, in order to capture correlations between
the various output parameters. The correlations are built into
the output parameters and consequently are reflected in any
arithmetic combination of parameters — no bootstrap is needed to
calculate correlations or their impact on quantities derived
from the fit parameters. The best-fit parameters (in fit.p)
are objects of type gvar.GVar.
Staggered quarks are used in
this simulation, so the has oscillating components as well as
normal components in its correlators.
The source codes (etas-Ds.py, Ds-Ds.py) and data files
(etas-Ds.h5, Ds-Ds.h5) are included with
the corrfitter distribution, in the examples/ directory.
The data are from the HPQCD collaboration.
Code¶
The main method for the form-factor code follows the pattern described
in Basic Fits:
from __future__ import print_function # makes this work for python2 and 3
import collections
import gvar as gv
import numpy as np
import corrfitter as cf
SHOWPLOTS = True
SVDCUT = 8e-5
def main():
data = make_data('etas-Ds.h5')
fitter = cf.CorrFitter(models=make_models())
p0 = None
for N in [1, 2, 3, 4]:
print(30 * '=', 'nterm =', N)
prior = make_prior(N)
fit = fitter.lsqfit(data=data, prior=prior, p0=p0, svdcut=SVDCUT)
print(fit.format(pstyle=None if N < 4 else 'v'))
p0 = fit.pmean
print_results(fit, prior, data)
if SHOWPLOTS:
fit.show_plots()
The Monte Carlo data are in a file named 'etas-Ds.h5'. We are doing
four fits, with 1, 2, 3, and 4 terms in the fit function. Each fit starts its
minimization at point p0, which is set equal to the mean values of the
best-fit parameters from the previous fit (p0 = fit.pmean). This reduces
the number of iterations needed for convergence in the N = 4 fit, for
example, from 162 to 45. It also makes multi-term fits more stable.
After the fit, plots of the fit data divided by the fit
are displayed by fit.show_plots(), provided
matplotlib is installed. A plot is made for each correlator, and the
ratios should equal one to within errors. To
move from one plot to the next press “n” on the keyboard; to move to a
previous plot press “p”; to cycle through different views of the data and fit
press “v”; and to quit the plots press “q”.
We now look at each other major routine in turn.
a) make_data¶
Method make_data('etas-Ds.h5') reads in the Monte Carlo data, averages
it, and formats it for use by corrfitter.CorrFitter:
def make_data(datafile):
""" Read data from datafile and average it. """
dset = cf.read_dataset(datafile)
return gv.dataset.avg_data(dset)
The data file etas-Ds.h5 is in hdf5 format. It contains four datasets:
>>> for v in dset.values():
... print(v)
<HDF5 dataset "3ptT15": shape (225, 16), type "<f8">
<HDF5 dataset "3ptT16": shape (225, 17), type "<f8">
<HDF5 dataset "Ds": shape (225, 64), type "<f8">
<HDF5 dataset "etas": shape (225, 64), type "<f8">
Each corresponds to Monte Carlo data for a single correlator, which
is packaged as a two-dimensional numpy array whose
first index labels the Monte Carlo sample, and whose second index labels
time. For example,
>>> print(dset['etas'][:, :])
[[ 0.305044 0.0789607 0.0331313 ..., 0.0164646 0.0332153 0.0791385]
[ 0.306573 0.0802435 0.0340765 ..., 0.0170088 0.034013 0.0801528]
[ 0.306194 0.0800234 0.0338007 ..., 0.0168862 0.0337728 0.0799462]
...,
[ 0.305955 0.0797565 0.0335741 ..., 0.0167847 0.0336077 0.0796961]
[ 0.305661 0.0793606 0.0333133 ..., 0.0165365 0.0333934 0.0792943]
[ 0.305365 0.079379 0.033445 ..., 0.0164506 0.0332284 0.0792884]]
is data for a two-point correlator describing the meson. Each
of the 225 lines is a different Monte Carlo sample for the correlator, and
has 64 entries corresponding to t=0,1...63. Note the periodicity
in this data.
Function gv.dataset.avg_data(dset) averages over the Monte Carlo samples
for all the correlators to compute their means and covariance matrix.
The end result is a dictionary whose keys are the keys used to
label the hdf5 datasets: for example,
>>> data = make_data('etas-Ds.h5')
>>> print(data['etas'])
[0.305808(29) 0.079613(24) 0.033539(17) ... 0.079621(24)]
>>> print(data['Ds'])
[0.2307150(73) 0.0446523(32) 0.0089923(15) ... 0.0446527(32)]
>>> print(data['3ptT16'])
[1.4583(21)e-10 3.3639(44)e-10 ... 0.000023155(30)]
Here each entry in data is an array of gvar.GVars representing Monte
Carlo averages for the corresponding correlator at different times. This
is the format needed by corrfitter.CorrFitter. Note that the different correlators
are correlated with each other: for example,
>>> print(gv.evalcorr([data['etas'][0], data['Ds'][0]]))
[[ 1. 0.96432174]
[ 0.96432174 1. ]]
shows a 96% correlation between the t=0 values in the and
correlators.
b) make_models¶
Method make_models() specifies the theoretical models that will be used
to fit the data:
def make_models():
""" Create models to fit data. """
tmin = 5
tp = 64
models = [
cf.Corr2(
datatag='etas', tp=tp, tmin=tmin,
a='etas:a', b='etas:a', dE='etas:dE',
),
cf.Corr2(
datatag='Ds', tp=tp, tmin=tmin,
a=('Ds:a', 'Dso:a'), b=('Ds:a', 'Dso:a'), dE=('Ds:dE', 'Dso:dE'),
),
cf.Corr3(
datatag='3ptT15', T=15, tmin=tmin, a='etas:a', dEa='etas:dE',
b=('Ds:a', 'Dso:a'), dEb=('Ds:dE', 'Dso:dE'),
Vnn='Vnn', Vno='Vno',
),
cf.Corr3(
datatag='3ptT16', T=16, tmin=tmin, a='etas:a', dEa='etas:dE',
b=('Ds:a', 'Dso:a'), dEb=('Ds:dE', 'Dso:dE'),
Vnn='Vnn', Vno='Vno',
)
]
return models
Four models are specified, one for each correlator to be fit. The first two
are for the and two-point correlators, corresponding to
entries in the data dictionary with keys 'etas' and 'Ds',
respectively.
These are periodic propagators, with period 64 (tp), and we want to
omit the first and last 5 (tmin) time steps in the correlator.
Labels for the fit parameters corresponding to the
sources (and sinks) are specified for each, 'etas:a' and 'Ds:a', as
are labels for the energy differences, 'etas:dE' and 'Ds:dE'. The
propagator also has an oscillating piece because this data comes from
a staggered-quark analysis. Sources/sinks and energy differences are
specified for these as well: 'Dso:a' and 'Dso:dE'.
Finally three-point models are specified for the data corresponding to
data-dictionary keys '3ptT15' and '3ptT16'. These share several
parameters with the two-point correlators, but introduce new parameters
for the transition matrix elements: 'Vnn' connecting normal states, and
'Vno' connecting normal states with oscillating states.
c) make_prior¶
Method make_prior(N) creates a priori estimates for each fit
parameter, to be used as priors in the fitter:
def make_prior(N):
""" Create priors for fit parameters. """
prior = gv.BufferDict()
# etas
metas = gv.gvar('0.4(2)')
prior['log(etas:a)'] = gv.log(gv.gvar(N * ['0.3(3)']))
prior['log(etas:dE)'] = gv.log(gv.gvar(N * ['0.5(5)']))
prior['log(etas:dE)'][0] = gv.log(metas)
# Ds
mDs = gv.gvar('1.2(2)')
prior['log(Ds:a)'] = gv.log(gv.gvar(N * ['0.3(3)']))
prior['log(Ds:dE)'] = gv.log(gv.gvar(N * ['0.5(5)']))
prior['log(Ds:dE)'][0] = gv.log(mDs)
# Ds -- oscillating part
prior['log(Dso:a)'] = gv.log(gv.gvar(N * ['0.1(1)']))
prior['log(Dso:dE)'] = gv.log(gv.gvar(N * ['0.5(5)']))
prior['log(Dso:dE)'][0] = gv.log(mDs + gv.gvar('0.3(3)'))
# V
prior['Vnn'] = gv.gvar(N * [N * ['0(1)']])
prior['Vno'] = gv.gvar(N * [N * ['0(1)']])
return prior
Parameter N specifies how many terms are kept in the fit functions. The
priors are stored in a dictionary prior. Each entry is an array, of
length N, with one entry for each term in the fit function.
Each entry is a Gaussian random
variable, an object of type gvar.GVar. Here we use the fact that
gvar.gvar() can make a list of gvar.GVars from a list of strings of the form
'0.1(1)': for example,
>>> print(gv.gvar(['1(2)', '3(2)']))
[1.0(2.0) 3.0(2.0)]
In this particular fit, we can assume that all the sinks/sources
are positive, and we can require that the energy differences be positive. To
force positivity, we use log-normal distributions for these parameters by
defining priors for 'log(etas:a)', 'log(etas:dE)' … rather than
'etas:a', 'etas:dE' … (see Postive Parameters). The a
priori values for these fit parameters are the logarithms of the values for
the parameters themselves: for example, each 'etas:a' has prior 0.3(3),
while the actual fit parameters, log(etas:a), have priors
log(0.3(3)) = -1.2(1.0).
We override the default priors for the ground-state energies in each case.
This is not unusual since dE[0], unlike the other dEs, is an energy,
not an energy difference. For the oscillating state, we require
that its mass be 0.3(3) larger than the mass. One could put
more precise information into the priors if that made sense given the goals
of the simulation. For example, if the main objective is a value for Vnn,
one might include fairly exact information about the and
masses in the prior, using results from experiment or from
earlier simulations. This would make no sense, however, if the goal is to
verify that simulations gives correct masses.
Note, finally, that a statement like
prior['Vnn'] = gv.gvar(N * [N* ['0(1)']]) # correct
is not the same as
prior['Vnn'] = N * [N * [gv.gvar('0(1)')]] # wrong
The former creates N ** 2 independent gvar.GVars, with one for each element
of Vnn; it is one of the most succinct ways of creating a large number of
gvar.GVars. The latter creates only a single gvar.GVar and uses it repeatedly for
every element Vnn, thereby forcing every element of Vnn to be equal
to every other element when fitting (since the difference between any two of
their priors is 0±0); it is almost certainly not what is desired.
Usually one wants to create the array of strings first, and then convert it to
gvar.GVars using gvar.gvar().
d) print_results¶
Method print_results(fit, prior, data) reports on the best-fit values
for the fit parameters from the last fit:
def print_results(fit, prior, data):
""" Report best-fit results. """
print('Fit results:')
p = fit.p # best-fit parameters
# etas
E_etas = np.cumsum(p['etas:dE'])
a_etas = p['etas:a']
print(' Eetas:', E_etas[:3])
print(' aetas:', a_etas[:3])
# Ds
E_Ds = np.cumsum(p['Ds:dE'])
a_Ds = p['Ds:a']
print('\n EDs:', E_Ds[:3])
print( ' aDs:', a_Ds[:3])
# Dso -- oscillating piece
E_Dso = np.cumsum(p['Dso:dE'])
a_Dso = p['Dso:a']
print('\n EDso:', E_Dso[:3])
print( ' aDso:', a_Dso[:3])
# V
Vnn = p['Vnn']
print('\n etas->V->Ds =', Vnn[0, 0])
# error budget
outputs = collections.OrderedDict()
outputs['metas'] = E_etas[0]
outputs['mDs'] = E_Ds[0]
outputs['Vnn'] = Vnn[0, 0]
inputs = collections.OrderedDict()
inputs['statistics'] = data # statistical errors in data
inputs['svd'] = fit.correction
inputs.update(prior) # all entries in prior
print('\n' + gv.fmt_values(outputs))
print(gv.fmt_errorbudget(outputs, inputs))
print('\n')
The best-fit parameter values are stored in dictionary p=fit.p,
as are the exponentials of the log-normal parameters.
We also turn energy differences into energies using numpy’s cummulative
sum function numpy.cumsum(). The final output is:
Fit results:
Eetas: [0.41618(12) 1.013(83) 1.46(36)]
aetas: [0.21834(16) 0.176(69) 0.30(14)]
EDs: [1.20165(16) 1.703(21) 2.24(22)]
aDs: [0.21467(20) 0.273(25) 0.47(19)]
EDso: [1.445(13) 1.68(12) 2.18(45)]
aDso: [0.0657(73) 0.082(31) 0.115(93)]
etas->V->Ds = 0.76716(85)
Finally we create an error budget for the
and masses, and for the ground-state transition amplitude
Vnn. The quantities of interest are specified in dictionary
outputs. For the error budget, we need another dictionary, inputs,
specifying various inputs to the calculation, here the Monte Carlo data,
the SVD corrections, and the
priors. Each of these inputs
contributes to the errors in the final results, as detailed in the
error budget:
Values:
metas: 0.41618(12)
mDs: 1.20165(16)
Vnn: 0.76716(85)
Partial % Errors:
metas mDs Vnn
-------------------------------------------
statistics: 0.03 0.01 0.09
svd: 0.00 0.00 0.03
log(etas:a): 0.00 0.00 0.01
log(etas:dE): 0.00 0.00 0.01
log(Ds:a): 0.00 0.00 0.02
log(Ds:dE): 0.00 0.00 0.02
log(Dso:a): 0.00 0.00 0.01
log(Dso:dE): 0.00 0.00 0.01
Vnn: 0.00 0.00 0.04
Vno: 0.00 0.00 0.01
-------------------------------------------
total: 0.03 0.01 0.11
The error budget shows, for example, that the largest sources of uncertainty in every quantity are the statistical errors in the input data.
e) SVD Cut¶
The fits need an SVD cut, svdcut=8e-5, because there are
only 225 random samples for
each of 69 data points. Following the recipe in Accurate Fits — SVD Cuts,
we determine the value of the SVD cut using a separate
script consisting of
import gvar as gv
import corrfitter as cf
def main():
dset = cf.read_dataset('etas-Ds.h5')
s = gv.dataset.svd_diagnosis(dset, models=make_models())
print('svdcut =', s.svdcut)
s.plot_ratio(show=True)
together with the make_models() method described above.
Running this script outputs a single line, telling us
to use svdcut=8e-5:
svdcut = 7.897481075407619e-05
It also displays a plot that shows how eigenvalues of the data’s correlation matrix that are below the SVD cutoff (dotted red line) are significantly underestimated:

The SVD cut adds additional uncertainty to the data to increase these eigenvalues so they do not cause trouble with the fit.
Results¶
The output from running the code is as follows:
============================== nterm = 1
Least Square Fit:
chi2/dof [dof] = 5.8e+03 [69] Q = 0 logGBF = -1.9877e+05
Settings:
svdcut/n = 8e-05/22 tol = (1e-08*,1e-10,1e-10) (itns/time = 28/0.1)
============================== nterm = 2
Least Square Fit:
chi2/dof [dof] = 2.2 [69] Q = 2.8e-08 logGBF = 1546.1
Settings:
svdcut/n = 8e-05/22 tol = (1e-08*,1e-10,1e-10) (itns/time = 29/0.1)
============================== nterm = 3
Least Square Fit:
chi2/dof [dof] = 0.58 [69] Q = 1 logGBF = 1593.5
Settings:
svdcut/n = 8e-05/22 tol = (1e-08*,1e-10,1e-10) (itns/time = 49/0.2)
============================== nterm = 4
Least Square Fit:
chi2/dof [dof] = 0.58 [69] Q = 1 logGBF = 1594
Parameters:
log(etas:a) 0 -1.52169 (74) [ -1.2 (1.0) ]
1 -1.74 (39) [ -1.2 (1.0) ]
2 -1.20 (47) [ -1.2 (1.0) ]
3 -1.27 (96) [ -1.2 (1.0) ]
log(etas:dE) 0 -0.87663 (28) [ -0.92 (50) ]
1 -0.52 (14) [ -0.7 (1.0) ]
2 -0.81 (65) [ -0.7 (1.0) ]
3 -0.66 (97) [ -0.7 (1.0) ]
log(Ds:a) 0 -1.53866 (95) [ -1.2 (1.0) ]
1 -1.298 (93) [ -1.2 (1.0) ]
2 -0.76 (40) [ -1.2 (1.0) ]
3 -1.11 (99) [ -1.2 (1.0) ]
log(Ds:dE) 0 0.18370 (14) [ 0.18 (17) ]
1 -0.691 (41) [ -0.7 (1.0) ]
2 -0.62 (37) [ -0.7 (1.0) ]
3 -0.76 (99) [ -0.7 (1.0) ]
log(Dso:a) 0 -2.72 (11) [ -2.3 (1.0) ]
1 -2.50 (38) [ -2.3 (1.0) ]
2 -2.17 (81) [ -2.3 (1.0) ]
3 -2.3 (1.0) [ -2.3 (1.0) ]
log(Dso:dE) 0 0.3680 (93) [ 0.41 (24) ]
1 -1.46 (49) [ -0.7 (1.0) ]
2 -0.69 (78) [ -0.7 (1.0) ]
3 -0.7 (1.0) [ -0.7 (1.0) ]
Vnn 0,0 0.76716 (85) [ 0.0 (1.0) ]
0,1 -0.491 (39) [ 0.0 (1.0) ]
0,2 0.39 (48) [ 0.0 (1.0) ]
0,3 0.05 (99) [ 0.0 (1.0) ]
1,0 0.060 (46) [ 0.0 (1.0) ]
1,1 0.38 (77) [ 0.0 (1.0) ]
1,2 0.03 (1.00) [ 0.0 (1.0) ]
1,3 0.002 (1.000) [ 0.0 (1.0) ]
2,0 -0.11 (24) [ 0.0 (1.0) ]
2,1 0.04 (1.00) [ 0.0 (1.0) ]
2,2 0.001 (1.000) [ 0.0 (1.0) ]
2,3 5e-05 +- 1 [ 0.0 (1.0) ]
3,0 -0.002 (981) [ 0.0 (1.0) ]
3,1 0.003 (1.000) [ 0.0 (1.0) ]
3,2 3e-05 +- 1 [ 0.0 (1.0) ]
3,3 5e-07 +- 1 [ 0.0 (1.0) ]
Vno 0,0 -0.778 (76) [ 0.0 (1.0) ]
0,1 0.30 (32) [ 0.0 (1.0) ]
0,2 -0.02 (88) [ 0.0 (1.0) ]
0,3 0.007 (0.998) [ 0.0 (1.0) ]
1,0 0.26 (44) [ 0.0 (1.0) ]
1,1 0.17 (96) [ 0.0 (1.0) ]
1,2 0.005 (0.999) [ 0.0 (1.0) ]
1,3 0.0001 (1.0000) [ 0.0 (1.0) ]
2,0 -0.14 (94) [ 0.0 (1.0) ]
2,1 0.003 (1.000) [ 0.0 (1.0) ]
2,2 0.0006 (1.0000) [ 0.0 (1.0) ]
2,3 1e-05 +- 1 [ 0.0 (1.0) ]
3,0 -0.02 (1.00) [ 0.0 (1.0) ]
3,1 -0.002 (1.000) [ 0.0 (1.0) ]
3,2 9e-06 +- 1 [ 0.0 (1.0) ]
3,3 3e-07 +- 1 [ 0.0 (1.0) ]
------------------------------------------------------
etas:a 0 0.21834 (16) [ 0.30 (30) ]
1 0.176 (69) [ 0.30 (30) ]
2 0.30 (14) [ 0.30 (30) ]
3 0.28 (27) [ 0.30 (30) ]
etas:dE 0 0.41618 (12) [ 0.40 (20) ]
1 0.597 (83) [ 0.50 (50) ]
2 0.45 (29) [ 0.50 (50) ]
3 0.52 (50) [ 0.50 (50) ]
Ds:a 0 0.21467 (20) [ 0.30 (30) ]
1 0.273 (25) [ 0.30 (30) ]
2 0.47 (19) [ 0.30 (30) ]
3 0.33 (32) [ 0.30 (30) ]
Ds:dE 0 1.20165 (16) [ 1.20 (20) ]
1 0.501 (21) [ 0.50 (50) ]
2 0.54 (20) [ 0.50 (50) ]
3 0.47 (46) [ 0.50 (50) ]
Dso:a 0 0.0657 (73) [ 0.10 (10) ]
1 0.082 (31) [ 0.10 (10) ]
2 0.115 (93) [ 0.10 (10) ]
3 0.10 (10) [ 0.10 (10) ]
Dso:dE 0 1.445 (13) [ 1.50 (36) ]
1 0.23 (11) [ 0.50 (50) ]
2 0.50 (39) [ 0.50 (50) ]
3 0.49 (48) [ 0.50 (50) ]
Settings:
svdcut/n = 8e-05/22 tol = (1e-08*,1e-10,1e-10) (itns/time = 20/0.1)
Fit results:
Eetas: [0.41618(12) 1.013(83) 1.46(36)]
aetas: [0.21834(16) 0.176(69) 0.30(14)]
EDs: [1.20165(16) 1.703(21) 2.24(22)]
aDs: [0.21467(20) 0.273(25) 0.47(19)]
EDso: [1.445(13) 1.68(12) 2.18(45)]
aDso: [0.0657(73) 0.082(31) 0.115(93)]
etas->V->Ds = 0.76716(85)
Values:
metas: 0.41618(12)
mDs: 1.20165(16)
Vnn: 0.76716(85)
Partial % Errors:
metas mDs Vnn
-------------------------------------------
statistics: 0.03 0.01 0.09
svd: 0.00 0.00 0.03
log(etas:a): 0.00 0.00 0.01
log(etas:dE): 0.00 0.00 0.01
log(Ds:a): 0.00 0.00 0.02
log(Ds:dE): 0.00 0.00 0.02
log(Dso:a): 0.00 0.00 0.01
log(Dso:dE): 0.00 0.00 0.01
Vnn: 0.00 0.00 0.04
Vno: 0.00 0.00 0.01
-------------------------------------------
total: 0.03 0.01 0.11
Note:
This is a relatively simple fit, taking only a second or so on a laptop.
Fits with only one or two terms in the fit function are poor, with
chi2/dofs that are significantly larger than one.Fits with three terms work well, and adding futher terms has almost no impact. The
 does not improve and parameters for the
added terms differ little from their prior values (since the data are
not sufficiently accurate to add new information).
does not improve and parameters for the
added terms differ little from their prior values (since the data are
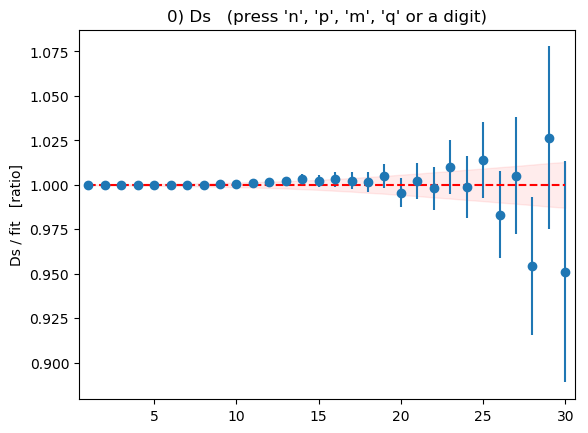
not sufficiently accurate to add new information).The quality of the fit is confirmed by the fit plots displayed at the end (press the ‘n’ and ‘p’ keys to cycle through the various plots, the ‘v’ key to cycle through different views of the data and fit, and the ‘q’ key to quit the plot). The plot for the
correlator,
for example, shows correlator data divided by fit result as a
function of t:
The points with error bars are the correlator data points; the fit result is 1.0 in this plot, of course, and the shaded band shows the uncertainty in the fit function evaluated with the best-fit parameters. Fit and data agree to within errors. Note how the fit-function errors (the shaded band) track the data errors. In general the fit function is at least as accurate as the data. It can be much more accurate, for example, when the data errors grow rapidly with
t.In many applications precision can be improved by factors of 2—3 or more by using multiple sources and sinks for the correlators. The code here is easily generalized to handle such a situation: each
corrfitter.Corr2andcorrfitter.Corr3inmake_models()is replicated with various different combinations of sources and sinks (one entry for each combination).
Testing the Fit¶
The for the fit above is low for a fit to 69 data points.
This would normally be evidence of a good fit, but, as
discussed in Goodness of Fit,
our SVD cut means that we need
to refit with added noise if we want to use as a measure of
fit quality.
We implement this test by adding the following code at the end of the
main() method above:
# check fit quality by adding noise
print('\n==================== add svd, prior noise')
noisy_fit = fitter.lsqfit(
data=data, prior=prior, p0=fit.pmean, svdcut=SVDCUT,
noise=True,
)
print(noisy_fit.format(pstyle=None))
p = key_parameters(fit.p)
noisy_p = key_parameters(noisy_fit.p)
print(' fit:', p)
print('noisy fit:', noisy_p)
print(' ', gv.fmt_chi2(gv.chi2(p - noisy_p)))
def key_parameters(p):
""" collect key fit parameters in dictionary """
ans = gv.BufferDict()
for k in ['etas:a', 'etas:dE', 'Ds:a', 'Ds:dE']:
ans[k] = p[k][0]
ans['Vnn'] = p['Vnn'][0, 0]
return ans
This reruns the fit but with random noise (associated with the SVD cut
and priors) added to the data. The result is still a good fit, but with
a signficantly higher , as expected:
==================== add svd, prior noise
Least Square Fit:
chi2/dof [dof] = 0.94 [69] Q = 0.63 logGBF = 1580.5
Settings:
svdcut/n = 8e-05/22* tol = (1e-08*,1e-10,1e-10) (itns/time = 260/1.1)
fit: {'etas:a': 0.21834(16),'etas:dE': 0.41618(12),'Ds:a': 0.21467(20),'Ds:dE': 1.20165(16),'Vnn': 0.76716(85)}
noisy fit: {'etas:a': 0.21831(16),'etas:dE': 0.41619(12),'Ds:a': 0.21457(27),'Ds:dE': 1.20162(18),'Vnn': 0.7660(16)}
chi2/dof = 0.72 [5] Q = 0.61
The noisy fit also agrees with the original fit about the most important parameters from the fit. This test provides further evidence that our fit is good.
A more complex test of the fitting protocol is obtained by using simulated fits: see Testing Fits with Simulated Data. We do this by adding
# simulated fit
for sim_pdata in fitter.simulated_pdata_iter(
n=2, dataset=cf.read_dataset('etas-Ds.h5'), p_exact=fit.pmean
):
print('\n==================== simulation')
sim_fit = fitter.lsqfit(
pdata=sim_pdata, prior=prior, p0=fit.pmean, svdcut=SVDCUT,
)
print(sim_fit.format(pstyle=None))
p = key_parameters(fit.pmean)
sim_p = key_parameters(sim_fit.p)
print('simulated - exact:', sim_p - p)
print(' ', gv.fmt_chi2(gv.chi2(p - sim_p)))
to the end of the main() method. This code does n=2 simulations
of the full fit, using the means fit.pmean from the last fit
as p_exact.
The code compares fit results with p_exact in each case,
and computes the of the difference between the leading parameters
and p_exact. The output is:
==================== simulation
Least Square Fit:
chi2/dof [dof] = 0.35 [69] Q = 1 logGBF = 1601.6
Settings:
svdcut/n = 8e-05/24 tol = (1e-08*,1e-10,1e-10) (itns/time = 58/0.2)
simulated - exact: {'etas:a': -0.00009(17),'etas:dE': -0.00007(12),'Ds:a': -2(200)e-06,'Ds:dE': -0.00002(16),'Vnn': -0.0003(11)}
chi2/dof = 0.11 [5] Q = 0.99
==================== simulation
Least Square Fit:
chi2/dof [dof] = 0.66 [69] Q = 0.99 logGBF = 1591.1
Settings:
svdcut/n = 8e-05/24 tol = (1e-08*,1e-10,1e-10) (itns/time = 50/0.2)
simulated - exact: {'etas:a': 0.00008(16),'etas:dE': 0.00007(12),'Ds:a': -0.00003(25),'Ds:dE': 0.00006(18),'Vnn': 0.0003(13)}
chi2/dof = 0.21 [5] Q = 0.96
This again confirms that the fit is working well.
Variation: Marginalization¶
Marginalization (see Marginalization) can speed up fits like
this one. To use an 8-term fit function, while tuning parameters for only
N terms, we change only four lines in the main program:
def main():
data = make_data('etas-Ds.h5')
fitter = cf.CorrFitter(models=make_models())
p0 = None
prior = make_prior(8) # 1
for N in [1, 2]: # 2
print(30 * '=', 'nterm =', N)
fit = fitter.lsqfit(
data=data, prior=prior, p0=p0, nterm=(N, N), svdcut=SVDCUT # 3
)
print(fit) # 4
p0 = fit.pmean
print_results(fit, prior, data)
if DISPLAYPLOTS:
fit.show_plots()
The first modification (#1) sets the prior to eight terms,
no matter what value N has.
The second modification (#2)
limits the
fits to N=1,2, because that is all that will be needed to get good
values for the leading term.
The third (#3) tells fitter.lsqfit to fit parameters from
only the first N terms in the fit function; parts of the prior that are
not being fit are incorporated (marginalized) into the fit data.
The last modification (#4) changes what is printed out.
The output
shows that
results for the leading term have converged by N=2 (and even N=1 is
pretty good):
============================== nterm = 1
Least Square Fit:
chi2/dof [dof] = 0.53 [69] Q = 1 logGBF = 1528.5
Parameters:
log(etas:a) 0 -1.52158 (87) [ -1.2 (1.0) ]
log(etas:dE) 0 -0.87660 (30) [ -0.92 (50) ]
log(Ds:a) 0 -1.5380 (15) [ -1.2 (1.0) ]
log(Ds:dE) 0 0.18375 (17) [ 0.18 (17) ]
log(Dso:a) 0 -2.56 (15) [ -2.3 (1.0) ]
log(Dso:dE) 0 0.382 (14) [ 0.41 (24) ]
Vnn 0,0 0.7664 (59) [ 0.0 (1.0) ]
Vno 0,0 -0.724 (55) [ 0.0 (1.0) ]
---------------------------------------------------
etas:a 0 0.21837 (19) [ 0.30 (30) ]
etas:dE 0 0.41620 (12) [ 0.40 (20) ]
Ds:a 0 0.21481 (32) [ 0.30 (30) ]
Ds:dE 0 1.20171 (20) [ 1.20 (20) ]
Dso:a 0 0.077 (11) [ 0.10 (10) ]
Dso:dE 0 1.465 (21) [ 1.50 (36) ]
Settings:
svdcut/n = 8e-05/35 tol = (1e-08*,1e-10,1e-10) (itns/time = 9/0.0)
============================== nterm = 2
Least Square Fit:
chi2/dof [dof] = 0.6 [69] Q = 1 logGBF = 1586.4
Parameters:
log(etas:a) 0 -1.52174 (76) [ -1.2 (1.0) ]
1 -1.68 (54) [ -1.2 (1.0) ]
log(etas:dE) 0 -0.87665 (29) [ -0.92 (50) ]
1 -0.51 (18) [ -0.7 (1.0) ]
log(Ds:a) 0 -1.5388 (11) [ -1.2 (1.0) ]
1 -1.34 (12) [ -1.2 (1.0) ]
log(Ds:dE) 0 0.18368 (15) [ 0.18 (17) ]
1 -0.707 (56) [ -0.7 (1.0) ]
log(Dso:a) 0 -2.72 (10) [ -2.3 (1.0) ]
1 -2.43 (20) [ -2.3 (1.0) ]
log(Dso:dE) 0 0.3688 (85) [ 0.41 (24) ]
1 -1.41 (34) [ -0.7 (1.0) ]
Vnn 0,0 0.76702 (94) [ 0.0 (1.0) ]
0,1 -0.471 (54) [ 0.0 (1.0) ]
1,0 0.072 (65) [ 0.0 (1.0) ]
1,1 0.04 (96) [ 0.0 (1.0) ]
Vno 0,0 -0.785 (59) [ 0.0 (1.0) ]
0,1 0.33 (22) [ 0.0 (1.0) ]
1,0 0.40 (49) [ 0.0 (1.0) ]
1,1 0.13 (98) [ 0.0 (1.0) ]
---------------------------------------------------
etas:a 0 0.21833 (16) [ 0.30 (30) ]
1 0.19 (10) [ 0.30 (30) ]
etas:dE 0 0.41618 (12) [ 0.40 (20) ]
1 0.60 (10) [ 0.50 (50) ]
Ds:a 0 0.21463 (24) [ 0.30 (30) ]
1 0.262 (31) [ 0.30 (30) ]
Ds:dE 0 1.20163 (18) [ 1.20 (20) ]
1 0.493 (28) [ 0.50 (50) ]
Dso:a 0 0.0661 (67) [ 0.10 (10) ]
1 0.088 (17) [ 0.10 (10) ]
Dso:dE 0 1.446 (12) [ 1.50 (36) ]
1 0.244 (84) [ 0.50 (50) ]
Settings:
svdcut/n = 8e-05/24 tol = (1e-08*,1e-10,1e-10) (itns/time = 20/0.1)
Fit results:
Eetas: [0.41618(12) 1.02(11)]
aetas: [0.21833(16) 0.19(10)]
EDs: [1.20163(18) 1.695(28)]
aDs: [0.21463(24) 0.262(31)]
EDso: [1.446(12) 1.690(89)]
aDso: [0.0661(67) 0.088(17)]
etas->V->Ds = 0.76702(94)
Values:
metas: 0.41618(12)
mDs: 1.20163(18)
Vnn: 0.76702(94)
Partial % Errors:
metas mDs Vnn
-------------------------------------------
statistics: 0.03 0.01 0.09
svd: 0.00 0.00 0.05
log(etas:a): 0.00 0.00 0.00
log(etas:dE): 0.00 0.00 0.00
log(Ds:a): 0.00 0.00 0.01
log(Ds:dE): 0.00 0.00 0.03
log(Dso:a): 0.00 0.00 0.00
log(Dso:dE): 0.00 0.00 0.01
Vnn: 0.00 0.00 0.06
Vno: 0.00 0.00 0.01
-------------------------------------------
total: 0.03 0.01 0.12
The tests applied to the first fit can be used here as well. For example,
setting noise=True in the
fit results in
==================== add svd, prior noise
Least Square Fit:
chi2/dof [dof] = 1 [69] Q = 0.37 logGBF = 1569.9
Settings:
svdcut/n = 8e-05/24* tol = (1e-08*,1e-10,1e-10) (itns/time = 18/0.1)
fit: {'etas:a': 0.21833(16),'etas:dE': 0.41618(12),'Ds:a': 0.21463(24),'Ds:dE': 1.20163(18),'Vnn': 0.76702(94)}
noisy fit: {'etas:a': 0.21834(16),'etas:dE': 0.41617(12),'Ds:a': 0.21470(23),'Ds:dE': 1.20166(17),'Vnn': 0.76743(88)}
chi2/dof = 0.74 [5] Q = 0.6
This suggests a good fit. The results are consistent with the original fit.
Variation: Chained Fit¶
Chained fits are used if fitter.lsqfit(...)
is replaced by fitter.chained_lsqfit(...) in main(). Following
the advice at the end of Chained Fits, we combine chained
fits with marginalization. Three parts of our original code need
modifications:
def main():
data = make_data('etas-Ds.h5')
models = make_models() # 1a
models = [
models[0], models[1], # 1b
dict(nterm=(2, 1), svdcut=6.3e-5), # 1c
(models[2], models[3]) # 1d
]
fitter = cf.CorrFitter(models=models) # 1e
p0 = None
for N in [1, 2, 3, 4]:
print(30 * '=', 'nterm =', N)
prior = make_prior(N)
fit = fitter.chained_lsqfit(data=data, prior=prior, p0=p0) # 2
print(fit.format(pstyle=None if N < 4 else 'm'))
p0 = fit.pmean
print_results(fit, prior, data)
if DISPLAYPLOTS:
fit.show_plots()
The first modification (#1) replaces the original list of models with
a structured list that instructs the (chained) fitter sequentially to:
- fit the
etas2-point correlator described inmodels[0](#1b);- fit the
Ds2-point correlator described inmodels[1](#1b);- reset fit parameters
nterm=(2, 1)(marginalize all but the first three states) andsvdcut=6.3e-5for subsequent fits (#1c);- fit simultaneously the two 3-point correlators described in
(models[2],models[3])(#1d).
The second modification (#2) replaces lsqfit by chained_lsqfit.
It also removes the SVD cutfrom the 2-point fits;
as discussed above (1c), the SVD cut is reintroduced for the 3-point
fits.
The output for N=4 terms is substantially shorter than for our
original code:
============================== nterm = 4
Least Square Fit:
chi2/dof [dof] = 0.68 [69] Q = 0.98 logGBF = 1599.9
Parameters:
log(etas:a) 0 -1.52143 (76) [ -1.2 (1.0) ]
1 -1.62 (35) [ -1.2 (1.0) ]
2 -1.22 (50) [ -1.2 (1.0) ]
3 -1.28 (97) [ -1.2 (1.0) ]
log(etas:dE) 0 -0.87656 (29) [ -0.92 (50) ]
1 -0.47 (12) [ -0.7 (1.0) ]
2 -0.78 (74) [ -0.7 (1.0) ]
3 -0.65 (98) [ -0.7 (1.0) ]
log(Ds:a) 0 -1.53910 (97) [ -1.2 (1.0) ]
1 -1.38 (13) [ -1.2 (1.0) ]
2 -0.81 (53) [ -1.2 (1.0) ]
3 -1.12 (99) [ -1.2 (1.0) ]
log(Ds:dE) 0 0.18366 (14) [ 0.18 (17) ]
1 -0.732 (56) [ -0.7 (1.0) ]
2 -0.67 (60) [ -0.7 (1.0) ]
3 -0.76 (99) [ -0.7 (1.0) ]
log(Dso:a) 0 -2.670 (46) [ -2.3 (1.0) ]
1 -2.07 (56) [ -2.3 (1.0) ]
2 -2.24 (99) [ -2.3 (1.0) ]
log(Dso:dE) 0 0.3698 (51) [ 0.41 (24) ]
1 -0.73 (50) [ -0.7 (1.0) ]
2 -0.75 (98) [ -0.7 (1.0) ]
Vnn 0,0 0.7675 (11) [ 0.0 (1.0) ]
0,1 -0.439 (36) [ 0.0 (1.0) ]
1,0 0.063 (53) [ 0.0 (1.0) ]
1,1 -0.006 (873) [ 0.0 (1.0) ]
Vno 0,0 -0.711 (15) [ 0.0 (1.0) ]
1,0 -0.26 (36) [ 0.0 (1.0) ]
---------------------------------------------------
etas:a 0 0.21840 (17) [ 0.30 (30) ]
1 0.198 (70) [ 0.30 (30) ]
2 0.30 (15) [ 0.30 (30) ]
3 0.28 (27) [ 0.30 (30) ]
etas:dE 0 0.41621 (12) [ 0.40 (20) ]
1 0.625 (78) [ 0.50 (50) ]
2 0.46 (34) [ 0.50 (50) ]
3 0.52 (51) [ 0.50 (50) ]
Ds:a 0 0.21457 (21) [ 0.30 (30) ]
1 0.252 (33) [ 0.30 (30) ]
2 0.45 (24) [ 0.30 (30) ]
3 0.33 (32) [ 0.30 (30) ]
Ds:dE 0 1.20161 (16) [ 1.20 (20) ]
1 0.481 (27) [ 0.50 (50) ]
2 0.51 (30) [ 0.50 (50) ]
3 0.47 (46) [ 0.50 (50) ]
Dso:a 0 0.0693 (32) [ 0.10 (10) ]
1 0.127 (71) [ 0.10 (10) ]
2 0.11 (10) [ 0.10 (10) ]
Dso:dE 0 1.4474 (74) [ 1.50 (36) ]
1 0.48 (24) [ 0.50 (50) ]
2 0.47 (46) [ 0.50 (50) ]
Settings:
svdcut/n = 6.3e-05/3 tol = (1e-08,1e-10,1e-10) (itns/time = 34/0.1)
fitter = chained fit
Chained Fits:
chi2/dof [dof] Q logGBF svd-n itns/time fit
------------------------------------------------------------------------
0.69 [28] 0.88 488.06 0 12/0.0 etas
0.75 [28] 0.83 850.45 0 16/0.0 Ds
0.52 [13] 0.91 261.41 3 6/0.0 (3ptT15,3ptT16)
------------------------------------------------------------------------
0.68 [69] 0.98 1599.9 3 34/0.1 all
Fit results:
Eetas: [0.41621(12) 1.042(78) 1.50(40)]
aetas: [0.21840(17) 0.198(70) 0.30(15)]
EDs: [1.20161(16) 1.682(27) 2.19(32)]
aDs: [0.21457(21) 0.252(33) 0.45(24)]
EDso: [1.4474(74) 1.93(24) 2.40(54)]
aDso: [0.0693(32) 0.127(71) 0.11(10)]
etas->V->Ds = 0.7675(11)
Values:
metas: 0.41621(12)
mDs: 1.20161(16)
Vnn: 0.7675(11)
Partial % Errors:
metas mDs Vnn
-------------------------------------------
statistics: 0.03 0.01 0.12
svd: 0.00 0.00 0.02
log(etas:a): 0.00 0.00 0.00
log(etas:dE): 0.00 0.00 0.00
log(Ds:a): 0.00 0.00 0.03
log(Ds:dE): 0.00 0.00 0.03
log(Dso:a): 0.00 0.00 0.00
log(Dso:dE): 0.00 0.00 0.00
Vnn: 0.00 0.00 0.05
Vno: 0.00 0.00 0.01
-------------------------------------------
total: 0.03 0.01 0.14
Again the results agree well with the original fit.
Fit results are listed from each step in the chain: first just
the etas 2-point correlator, then the Ds 2-point
correlator, and finally a combined fit of both 3-point
correlators. One might try less marginalization (e.g.,
nterm=(1,1)) to check that results are stable. Also one might
test the fits, as above.
Chained fits are particularly useful for very large data sets (much larger than this one). Also marginalizing extraneous variables in the 3-point fits can make fitting more robust (because it is simpler).
Mixing¶
Code to analyze - mixing is very similar to the code above for
a transition form factor. The main() and make_data() functions are
identical, except that here data are read from file 'Ds-Ds.h5' and
the appropriate SVD cut is svdcut=0.003 (see Accurate Fits — SVD Cuts).
We need models for the two-point correlator, and for two three-point
correlators describing the to transition:
def make_models():
""" Create models to fit data. """
tmin = 3
tp = 64
models = [
cf.Corr2(
datatag='Ds', tp=tp, tmin=tmin,
a=('a', 'ao'), b=('a', 'ao'), dE=('dE', 'dEo'), s=(1., -1.),
),
cf.Corr3(
datatag='DsDsT18', T=18, tmin=tmin,
a=('a', 'ao'), dEa=('dE', 'dEo'), sa=(1., -1),
b=('a', 'ao'), dEb=('dE', 'dEo'), sb=(1., -1.),
Vnn='Vnn', Voo='Voo', Vno='Vno', symmetric_V=True,
),
cf.Corr3(
datatag='DsDsT15', T=15, tmin=tmin,
a=('a', 'ao'), dEa=('dE', 'dEo'), sa=(1., -1),
b=('a', 'ao'), dEb=('dE', 'dEo'), sb=(1., -1.),
Vnn='Vnn', Voo='Voo', Vno='Vno', symmetric_V=True,
)
]
return models
The initial and final states in the three-point correlators are the same
here so we set parameter symmetricV=True in corrfitter.Corr3.
The prior is also similar to the previous case:
def make_prior(N):
""" Create priors for fit parameters. """
prior = gv.BufferDict()
# Ds
mDs = gv.gvar('1.2(2)')
prior['log(a)'] = gv.log(gv.gvar(N * ['0.3(3)']))
prior['log(dE)'] = gv.log(gv.gvar(N * ['0.5(5)']))
prior['log(dE)'][0] = gv.log(mDs)
# Ds -- oscillating part
prior['log(ao)'] = gv.log(gv.gvar(N * ['0.1(1)']))
prior['log(dEo)'] = gv.log(gv.gvar(N * ['0.5(5)']))
prior['log(dEo)'][0] = gv.log(mDs + gv.gvar('0.3(3)'))
# V
nV = int((N * (N + 1)) / 2)
prior['Vnn'] = gv.gvar(nV * ['0.0(5)'])
prior['Voo'] = gv.gvar(nV * ['0.0(5)'])
prior['Vno'] = gv.gvar(N * [N * ['0.0(5)']])
return prior
We use log-normal distributions for the energy differences, and
amplitudes.
We store only the upper triangular parts of the Vnn and Voo matrices
since they are symmetrical (because symmetricV=True is set).
A minimal print_results() function is:
def print_results(fit, prior, data):
""" Print results of fit. """
outputs = collections.OrderedDict()
outputs['mDs'] = fit.p['dE'][0]
outputs['Vnn'] = fit.p['Vnn'][0]
inputs = collections.OrderedDict()
inputs['statistics'] = data # statistical errors in data
inputs['Ds priors'] = {
k:prior[k] for k in ['log(a)', 'log(dE)', 'log(ao)', 'log(dEo)']
}
inputs['V priors'] = {
k:prior[k] for k in ['Vnn', 'Vno', 'Voo']
}
print('\n' + gv.fmt_values(outputs))
print(gv.fmt_errorbudget(outputs, inputs))
Running the mixing code gives the following output for N=4:
============================== nterm = 4
Least Square Fit:
chi2/dof [dof] = 0.68 [53] Q = 0.96 logGBF = 1559.9
Parameters:
log(a) 0 -1.5555 (58) [ -1.2 (1.0) ]
1 -1.64 (35) [ -1.2 (1.0) ]
2 -0.74 (16) [ -1.2 (1.0) ]
3 -1.40 (91) [ -1.2 (1.0) ]
log(dE) 0 0.27128 (55) [ 0.18 (17) ]
1 -0.93 (22) [ -0.7 (1.0) ]
2 -0.87 (15) [ -0.7 (1.0) ]
3 -0.83 (99) [ -0.7 (1.0) ]
log(ao) 0 -2.76 (12) [ -2.3 (1.0) ]
1 -2.14 (12) [ -2.3 (1.0) ]
2 -2.60 (76) [ -2.3 (1.0) ]
3 -2.47 (97) [ -2.3 (1.0) ]
log(dEo) 0 0.341 (11) [ 0.41 (24) ]
1 -1.27 (19) [ -0.7 (1.0) ]
2 -0.65 (92) [ -0.7 (1.0) ]
3 -0.57 (98) [ -0.7 (1.0) ]
Vnn 0 0.1065 (20) [ 0.00 (50) ]
1 -0.005 (30) [ 0.00 (50) ]
2 0.001 (85) [ 0.00 (50) ]
3 -0.15 (37) [ 0.00 (50) ]
4 0.004 (500) [ 0.00 (50) ]
5 0.0005 (4993) [ 0.00 (50) ]
6 0.002 (500) [ 0.00 (50) ]
7 0.00006 (50000) [ 0.00 (50) ]
8 3e-06 +- 0.5 [ 0.00 (50) ]
9 2e-08 +- 0.5 [ 0.00 (50) ]
Vno 0,0 -0.2104 (91) [ 0.00 (50) ]
0,1 -0.006 (43) [ 0.00 (50) ]
0,2 0.06 (17) [ 0.00 (50) ]
0,3 -0.03 (48) [ 0.00 (50) ]
1,0 0.016 (89) [ 0.00 (50) ]
1,1 -0.0003 (4998) [ 0.00 (50) ]
1,2 -3e-05 +- 0.5 [ 0.00 (50) ]
1,3 0.0002 (5000) [ 0.00 (50) ]
2,0 0.03 (12) [ 0.00 (50) ]
2,1 0.002 (500) [ 0.00 (50) ]
2,2 2e-07 +- 0.5 [ 0.00 (50) ]
2,3 1e-07 +- 0.5 [ 0.00 (50) ]
3,0 -0.04 (48) [ 0.00 (50) ]
3,1 -0.0005 (5000) [ 0.00 (50) ]
3,2 2e-07 +- 0.5 [ 0.00 (50) ]
3,3 -6e-10 +- 0.5 [ 0.00 (50) ]
Voo 0 -0.091 (60) [ 0.00 (50) ]
1 0.02 (10) [ 0.00 (50) ]
2 -0.05 (43) [ 0.00 (50) ]
3 -0.02 (49) [ 0.00 (50) ]
4 -0.004 (500) [ 0.00 (50) ]
5 -0.0005 (5000) [ 0.00 (50) ]
6 -0.0008 (5000) [ 0.00 (50) ]
7 -4e-07 +- 0.5 [ 0.00 (50) ]
8 -2e-07 +- 0.5 [ 0.00 (50) ]
9 -1e-10 +- 0.5 [ 0.00 (50) ]
------------------------------------------------------
a 0 0.2111 (12) [ 0.30 (30) ]
1 0.194 (67) [ 0.30 (30) ]
2 0.477 (75) [ 0.30 (30) ]
3 0.25 (22) [ 0.30 (30) ]
dE 0 1.31164 (72) [ 1.20 (20) ]
1 0.395 (86) [ 0.50 (50) ]
2 0.419 (64) [ 0.50 (50) ]
3 0.44 (43) [ 0.50 (50) ]
ao 0 0.0633 (79) [ 0.10 (10) ]
1 0.118 (14) [ 0.10 (10) ]
2 0.074 (56) [ 0.10 (10) ]
3 0.085 (82) [ 0.10 (10) ]
dEo 0 1.407 (15) [ 1.50 (36) ]
1 0.282 (55) [ 0.50 (50) ]
2 0.52 (48) [ 0.50 (50) ]
3 0.56 (55) [ 0.50 (50) ]
Settings:
svdcut/n = 0.002/9 tol = (1e-08*,1e-10,1e-10) (itns/time = 81/0.4)
Values:
mDs: 1.31164(72)
Vnn: 0.1065(20)
Partial % Errors:
mDs Vnn
-------------------------------
statistics: 0.05 1.16
Ds priors: 0.02 0.51
V priors: 0.00 1.37
-------------------------------
total: 0.06 1.88
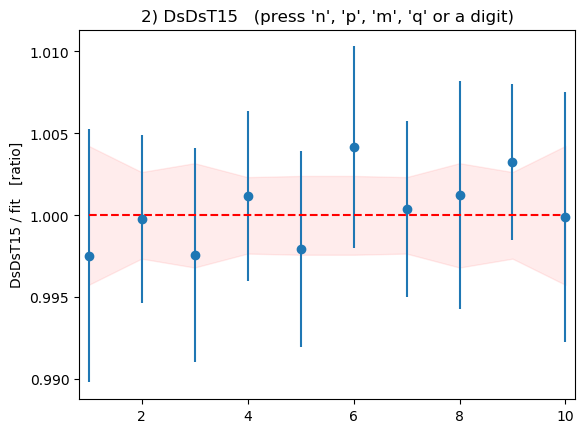
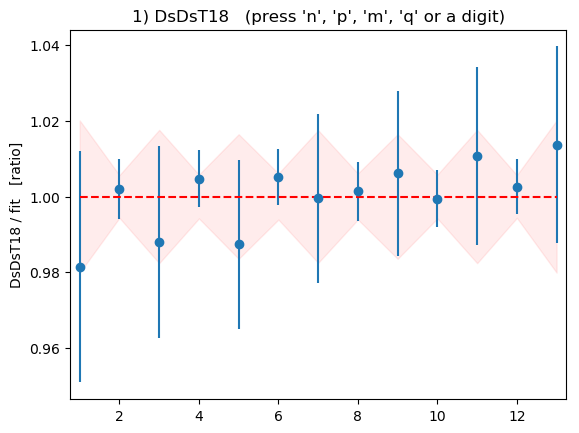
The fits for individual correlators look good:
|
|
|